
Why Jay Bhattacharya Does Not Belong Anywhere Near the NIH: Part Two
A flawed study raises serious questions about research integrity

As Trump crashes the machinery of the world’s leading life sciences research infrastructure, flipping circuit breakers and pouring sand in the gears, it is critical to consider the expertise and character of those he has picked to restart it. In part one, we identified six significant flaws in the design of Jay Bhattacharya’s study that played a key role in falsely minimizing the risk of COVID. Part Two considers their analysis and interpretation of the study, bringing the red flag count to a baker’s dozen.

The study was a serosurvey that attempted to measure the prevelance of COVID antibodies in the blood of residents of Santa Clara, CA. The single greatest challenge in any serosurvey is getting a random sample of blood. People do not give blood samples casually. In the early days of COVID it was difficult to get tested, so many of those with significant illness had not been diagnosed. The study design suggests they did not take this self-selection bias seriously.
1. They recruited subjects with a Facebook Ad, to which, it is likely, less than 5% of viewers responded. (The authors don’t report the numbers.)
2. The extremely high case fatality rate (5-8%) in Santa Clara at that time guarantees that there were many unreported cases of significant illness in the county.
3. They collected samples on a Friday and Saturday, during a shelter in place order, further requiring a high level of motivation among participants.
4. Bhattacharya’s wife had sent out an email to a middle school listserv, actively encouraging community members who suspected they had COVID to participate.
How did Bhattacharya’s team assess and address selection bias? How did they present the study results? How did they respond to criticisms of the study? Were they open and honest about the limitations of the study and any possible conflicts of interest?
The answers to these questions raise a flock of red flags.
Red Flag #7 Not comparing non-participants to participants
One standard tool for evaluating selection bias is to collect information on non-response. This can be done by directly asking non-respondents their reason for participating. This is possible if potential participants are being contacted directly, but that is challenging if not impossible with a Facebook ad. Another approach would be to conduct a separate survey of the general population and ask them about recent illnesses or disease symptoms. If the frequency and severity of symptoms in the general population is the same as participants, we can have some confidence that a history of symptoms did not motivate participation. This was neither done nor considered in this study.

Red Flag #8 Not assessing motivation for participating.
The simplest way to address concerns as to participants’ reasons for participating is painfully obvious. Ask them. Why did you participate? Do you think you or someone you know might have had COVID? They did none of this.
They at least asked subjects about a list of symptoms over the past two weeks and over the past two months. What they found is that 82% of those who tested positive had experienced at least one of the symptoms on their list in the past two months. Those who had symptoms were more than twice as likely to test positive. And their symptom list was woefully inadequate.
Their list didn’t include muscle aches, fatigue, or headaches, which are three of the six most common COVID symptoms. So, we don’t even know if those with none of the listed symptoms actually had no symptoms. They also included no information on the severity or duration of symptoms. The closest they come to considering severity is to look at the prevalence of combined cough and fever, but only half of symptomatic COVID cases have a cough, so far fewer than half would be represented by that pairing. Even this weak tool provides evidence that the antibody prevalence was associated with severity of symptoms.

Despite all of this, they routinely refer to those testing positive as having few or no symptoms. In fact, the authors use this very limited analysis in a bizarre attempt to prove that self-selection bias was not a problem by analyzing this as if it captured all of symptom based participation despite the fact that they don’t consider three of the six most common COVID symptoms, don’t ask about severity or duration of symptoms, and don’t ask if symptoms motivated their participation.
It seems as if the only problems that concerned the authors were those that might reduce their estimate of COVID prevalence. At one point they even state, “we were concerned about the apparent over-representation of wealthy and healthy-appearing participants. This bias is consistent with a common type of healthy volunteer bias which leads to under-participation of sicker populations”. If you are looking for antibodies in asymptomatic people, why would you be concerned that they look healthy? If you cluster your sampling stations in affluent communities, why are you surprised that subjects appear wealthy?
The authors bias towards methods and procedures that lead towards elevated risk estimates becomes clear if we look at adjustments they made to the raw data. Or, in this next example, adjustments they didn’t make.
Red Flag #9 Not correcting for selection bias
Astonishingly, they do not attempt to correct for or assess the bias likely to have resulted from the e-mail sent by Bhattacharya’s wife. They don’t even acknowledge its existence in the initial preprint and bury it with vague references in the supplementary material for other versions, arguably deserving of its own red flag. Had they been determined to minimize bias, they would have simply excluded subjects from the relevant zip code. At a minimum, they should have compared antibody prevalence in this ZIP code to the larger population to determine if there was a self-selection bias. If they had assessed, they might have been able to do something about it. No effort. Penalty flag.

They do adjust for demographic factors such as race and sex, which remarkably increases antibody prevalence by 84%. This big a change in their results due to a reweighting algorithm should have raised concerns among the authors about the quality of their data. Instead, they treat it as further evidence of their thesis. This adjustment and its blind acceptance deserve a closer look and earns a red flag all its own.
Red Flag #10 Maladjustment
The raw data (with the above mentioned flaws) generates an estimated COVID prevalence of 1.5%. The authors then use a series of adjustments that, with a wave of a statistical magic wand, increase that estimate to 2.8%. Their description referring to “iterative proportional fitting”, “bootstrap procedures”, and “propagating uncertainty” makes the analysis seem very sophisticated. But all the description does is obscure what is happening.
If we simply look at the data in context, we can see why it raised their estimate of prevalence so dramatically. It suggests that either the authors don’t understand their data, or they don’t want us to understand their data.

These data make it clear that the authors do not have a random sample. The sample had twice as many whites, about half the Asians, and less than a third of the Hispanics as the population of Santa Clara County. Instead of asking why they have this extremely nonrandom selection, they presume to solve it by fitting, bootstrapping, and propagating. They don’t ask why the relative rate of COVID antibodies is so high in their Hispanic group when ethnicity does not appear to have had a strong relationship with COVID statewide.
Remember that only a tiny fraction of those given the opportunity to test did so. The authors don’t ever seem to seriously explore why they participated. They don’t consider the possibility that many in the Hispanic community worked at jobs that make it difficult to take off on a Friday, or even a Saturday, to get tested. They don’t acknowledge that their sampling locations were concentrated in one area of the county that might be closer to those wealthy white people they worried about. That could well mean that the few Hispanics that did participate had reason to be particularly curious about their COVID status. In other words, the high antibody prevalence and low participation rate among Hispanics might be evidence of a self-selection bias rather than an aberration. If so, their adjustment scheme simply amplified that bias.
The fancy statistics make it clear that the authors do not lack for intelligence. But that only makes the study worse, because it suggests they knew exactly what they were doing. The fact that the authors consistently ignore adjustments that might have decreased their estimate of the prevalence of COVID antibodies while including any adjustment that would increase it raises serious concerns about their intellectual honesty.
Red Flag #11 Conflict of Interest
It might seem from the accumulated red flags that Bhattacharya and his team didn’t look for weaknesses in their data, like they didn’t want to look. If so, why? The fact that they had declared their expected findings before collecting their first blood sample, raises the possibility that they were protecting their reputations. His co-author, John Ioannidis, has written about this bias. A second possible reason revealed itself even before the manuscript was released.
Just two days after the completion of sample collection, David Neeleman, CEO of Jet Blue, wrote an opinion piece in which he revealed the essence of the study’s findings and mentioned his regular discussions with the study’s authors. Despite this, the authors of the study never declare a conflict of interest and insist that Neeleman had no impact on their work even after it was revealed that Neeleman had provided $5,000 to support their research. He had even told them that Elon Musk would be interested in funding a much larger, national study. The fact that he was the first to publicly announce their work provides clear evidence that his role was anything but hands off.
Funding from one of the industries most severely affected by COVID travel restrictions represents a clear conflict of interest and raises a red flag. Hiding and denying that conflict earns a bonus flag.
Red Flag #12 Ignoring Critics
Many of the flaws mentioned here have been raised by others. Many of those criticisms were ignored, dismissed, or even ridiculed by the authors. Bhattacharya even went so far as to write a piece insisting that the Stanford faculty members who refused to support his research did so because they were trying to develop their own antibody test.
Even as COVID, the ultimate critic, proved their numbers to be wildly wrong (see below), they insisted they were right. None of the issues listed above was seriously addressed in the published paper when it was released a year later. Instead, Bhattacharya used the paper’s publication in a peer reviewed journal to dismiss critics.

The fact that they got it published with all these flaws is more an indictment of peer review than a measure of the paper’s quality. And perhaps the influence of Ioannidis, who was on the journal’s editorial board at the time it was published.
Red Flag #13 On the Media
Bhattacharya has suggested releasing the paper as a preprint was a routine choice, but use of preprints in medical research was anything but routine. Preprints were not new to science, but the preprint server for medical science, medrXiv.org, had only existed 10 months and Bhattacharya had never released a preprint before. Preprints are a great innovation, allowing for the immediate release of research results and providing a vital function during COVID, but their use in this case meant that there had been no opportunity to critique the study before its conclusions were shared with the world. And the authors did everything they could to make that happen. They appeared everyplace from CNN and Fox to YouTube. The hedge fund manager on the team penned an op-ed for the Wall Street Journal. Again and again they declared that COVID is no worse than the flu. The fact that they were wrong did not stop their assertion from permeating the COVID debate.

One other organization that picked up on their work was the American Institute for Economic Research (AIER), which published an extended piece lionizing John Ioannidis and welcoming his findings. In October, they brought Jay Bhattacharya together with two other academicians to create the infamous Great Barrington Declaration (GBD), which claimed that the mass infection of “not vulnerable” people, none of whom were vaccinated at the time, would lead to herd immunity and end the pandemic in 3-6 months. The next four months saw the worst spike in COVID deaths of the entire pandemic.
Were they right?
Viruses have little patience for bad science. If the infection fatality rate (IFR) were 0.17%, as they asserted, infecting everyone in the US with no protection from the vaccine would result in a maximum of 521,000 COVID deaths in the United States. We passed that number on March 1, 2021, before the paper was even published on our way to the current death toll of 1.2 million.
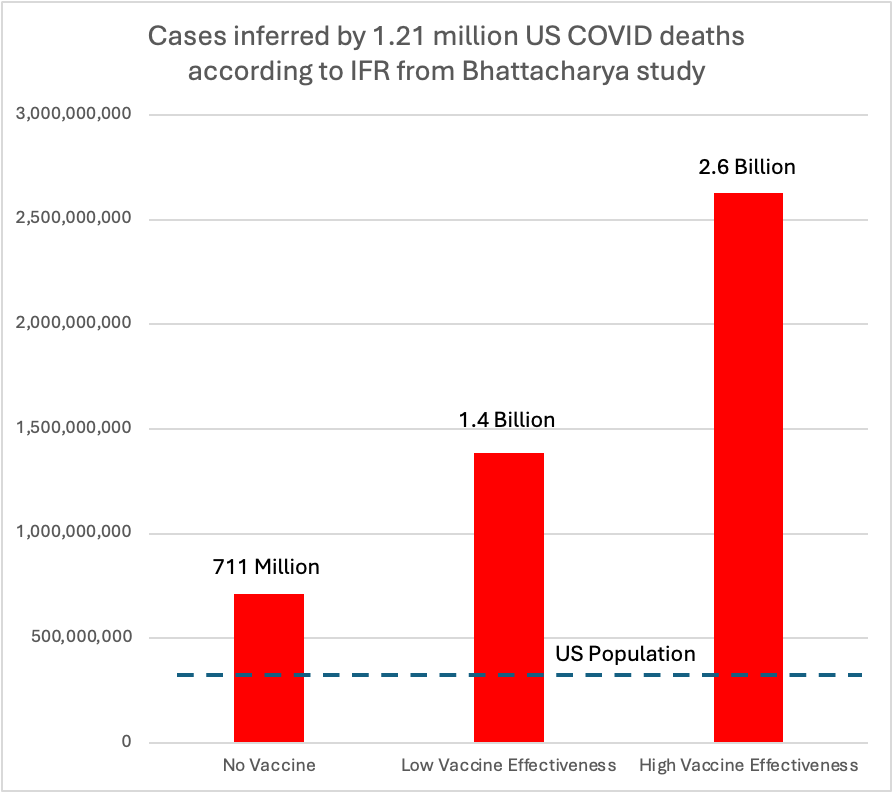
Without the vaccine, at their estimated IFR of 0.17%, 1.2 million deaths would imply to 711 million cases, which is a lot for a country of 330 million. But available estimates suggest we would have had two to three times the observed number of deaths without the vaccine, suggesting Bhattacharya’s estimate of IFR would imply between 1.3 and 2.2 billion infection in the US, suggesting a 4 to 8-fold error in their estimate
Bottom Line
They were wrong. The reasons lie in their 13+ red flags. We all make mistakes, but 13 is a lot and raises serious concerns about his suitability to lead NIH. More concerning is the question of character and integrity. His continued insistence that he is correct in the face of overwhelming evidence to the contrary, coupled with his repeated failure to acknowledge conflicts of interest has had a devastating impact on public health and disqualifies him as a researcher, much less a leader of research.
In the through-the-looking-glass world of Trump politics, none of this matters. He will be confirmed by a dutiful Senate. But I, for one, want to go on the record by unequivocally stating that Jay Bhattacharya belongs nowhere near the NIH.
